|
DATABASE - "Corpus CEIPAC" |
|
|
Remesal Rodríguez, J.; Berni Millet, P.; Aguilera Martín, A., "Amphoreninschriften und ihre elektronische Bearbeitung". |
| 0.- Introducción. La base de datos CEIPAC tuvo su constitución física en el año 1989, fecha de comienzo de nuestra excavación en el Monte Testaccio y de la formación del Grupo. La base de datos CEIPAC es una base de datos básicamente enfocada a la informatización de la epigrafía anfórica. Con ella, el CEIPAC pretende ser un referente para los estudios de carácter epigráfico, especialmente para aquellos dedicados a lo que Dressel denominó minuzie epigrafiche, tan importantes para el conocimiento de las características internas de la lengua latina. Pero la base de datos del CEIPAC también pretender servir para el estudio y clarificación de muchos aspectos de la economía romana, especialmente aquellos dedicados a la producción y el comercio de alimentos en la antigüedad. Del mismo modo, nuestra base de datos pretende también servir para precisar las dataciones estratigráficas de muchas excavaciones arqueológicas que en la actualidad desdeñan esta cerámica como fósil director. De todos los tipos anfóricos, las ánforas Dressel 20 siguen siendo, aún hoy, las ánforas mejor conocidas gracias a tres circunstancias:
El punto de partida de nuestra investigación y nuestra base de datos fue el ánfora Dressel 20, dada la gran información que contiene. 1.- Metodología de la base de datos.
La base de datos CEIPAC dispone en la actualidad de más de 20.000 registros. Durante la primera mitad de los años 90 se creó nuestra primera base de datos informática, que funcionaba con un gestor de bases de datos de IBM y que sólo podía consultarse localmente. Fue a partir de 1998, con el desarrollo de Internet y las posibilidades de acceso a la información que esta nueva herramienta ofrecía desde cualquier lugar, cuando la base de datos comenzó a migrarse hacia un sistema on-line, que es el que actualmente utilizamos. La base de datos tiene dos objetivos principales, que a su vez están coligados: - El primero es conseguir un sistema de gestión virtual y corporativa, donde el trabajo no tenga límites ni temporales ni espaciales. La primera parte, la virtualidad del sistema, se ha conseguido estableciendo un servidor web al que se puede acceder desde cualquier parte del mundo sin importar el día o la hora. La segunda parte, la corporatividad del sistema, se ha conseguido permitiendo que la base de datos se nutra de información desde diversas partes del mundo al unísono. Para ello hemos intentado contar con los mejores especialistas en cada tipo anfórico, ofreciendo la oportunidad de pertenecer al proyecto a todos aquellos investigadores dedicados al estudio de dicha epigrafía. Para gestionar el trabajo de los diversos especialistas, la base de datos ofrece cuatro perfiles de usuario: El primer perfil es el de los supervisores; la figura del supervisor es la de un investigador experto en un aspecto concreto de la epigrafía anfórica. Las funciones del Supervisor son las de crear y coordinar un grupo de trabajo para el procesado de la información epigráfica sobre un tema concreto, normalmente sobre un tipo anfórico determinado. También el Supervisor tiene acceso a modificar algunas informaciones sobre la tipología anfórica de la que es especialista o la creación o modificación de los diversos diccionarios prosopográficos que están previstos para el futuro de la base de datos. En definitiva, cada supervisor es el responsable de dirigir el debate sobre las cuestiones epigráficas o tipológicas que conlleva un determinado tipo de ánfora, además de contribuir a mejorar el uso de la aplicación informática, pues entre sus funciones también está la de dar el visto bueno y depurar la información trabajada por los colaboradores. El segundo nivel es el de colaborador. Su perfil se acomoda al de todo investigador que quiera participar en el llenado de la base de datos mediante la aplicación virtual. El colaborador tiene acceso a todos los datos, herramientas y recursos metodológicos para realizar su trabajo pero no puede modificar directamente ninguno de ellos, pues su juicio sobre un determinado criterio debe pasar el examen del supervisor correspondiente para poder ser aceptado.
El tercer perfil es el de invitado; para ser invitado únicamente es necesario dirigirse al CEIPAC demandando un password de acceso a la base de datos. El perfil de invitado es el de un investigador que tiene acceso a la consulta de todo el volumen de datos epigráficos; es el caso, por ejemplo, de un arqueólogo que necesita datar un estrato a partir de la información contenida en la base de datos o de un investigador que necesita información para estudiar y publicar sus inscripciones. Sin embargo, no tiene acceso a los recursos ni a la documentación de vaciado. Si el invitado decide participar en el proyecto y resuelve incorporarse y formar parte del grupo que trabaja en el mismo, su perfil cambiará inmediatamente al de colaborador o al de supervisor.
Finalmente, existe un cuarto perfil, el perfil Anónimo. Se ha creado con la intención de que cualquier internauta pueda acceder a un ejemplo de la base de datos. Tiene a su disposición algunas herramientas de búsqueda pero sus consultas se realizan siempre sobre un volumen limitado de datos de muestra. A día de hoy participan en la base de datos CEIPAC 40 investigadores entre supervisores y colaboradores y 45 investigadores invitados. - Esta corporatividad nos permite implementar el segundo objetivo del que hemos hablado anteriormente: la creación de un estándar de referencia para todos los estudios relacionados con la epigrafía anfórica. En efecto, el segundo objetivo del CEIPAC es la institución de un espacio común de investigación para los investigadores sobre el tema. De este modo se puede crear un sistema de documentación a partir de las ideas y propuestas comunes de todos los investigadores asociados, de forma que se cree un estándar de referencia para nuestros estudios. Este espacio común permite que la documentación, los recursos y la metodología para gestionar la base de datos se conviertan en las herramientas didácticas que formen a nuevos investigadores. El estándar de referencia debe ser tanto un estándar científico como técnico. En éste último sentido, para conseguir el estándar de referencia técnico hemos partido de la experiencia que acumulamos en la gestión de bases de datos desde 1989. En la actualidad disponemos de un servidor propio con software libre. Todas las aplicaciones y módulos corren en un sistema operativo Linux sin coste alguno.
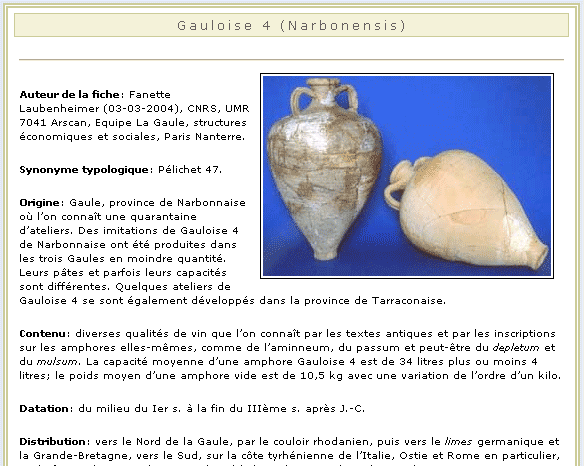
La documentación de soporte sobre el uso del sistema y la interficie se han traducido en gran parte a otros idiomas: de momento la base de datos corre en español, inglés y francés y se está traduciendo al alemán e italiano. También se ha invertido un gran esfuerzo en desarrollar un espacio metodológico virtual corporativo donde los colaboradores puedan consultar la documentación necesaria para saber cómo vaciar la epigrafía contenida en las diferentes referencias bibliográficas. Conceptualmente, la base de datos está diseñada partiendo de la idea de que cada objeto con valor epigráfico debe tener un tratamiento único y por ello para cada objeto se debe abrir una ficha. Normalmente, en nuestro caso, cada objeto con valor epigráfico suele ser un ánfora. Pero no todas las ánforas suelen tener la misma epigrafía, pues ésta varía según el tipo anfórico, ni todas las ánforas de un mismo tipo anfórico conservan toda la epigrafía típica de su forma, puesto que no siempre llegan a nosotros enteras. Por ello, la base de datos está dividida en cinco tablas diferentes. La primera tabla, es la tabla Objeto. La tabla Objeto es la entidad principal del modelo de base de datos y se encarga de describir los atributos de Instrumentum domesticum que son motivo de nuestro estudio. A cada objeto epigráfico se le da un número de inventario CEIPAC y se le abre aquí una ficha en la que se describen datos tales como la primera referencia bibliográfica del objeto, la tipología del objeto [figura 6], su lugar de hallazgo (con los datos de excavación específica, la localidad y el país de hallazgo, en forma de atributo UFI, Unique Feature ID, obtenidos a partir de la base de datos GEOnet de la NIMA (http://earth-info.nima.mil/gns/html/index.html), la Nacional Imagery and Mapping Agency de los Estados Unidos). También en esta tabla Objeto se documenta, si se conoce, el lugar de producción del objeto, el museo o lugar de conservación, la datación cronológica del objeto o toda la bibliografía que cita a ese objeto concreto. También, en la misma ficha se documenta sumariamente el tipo de epigrafía que aún se conserva: si se conserva o conservan sellos, grafitos o tituli picti.
Además de la Tabla Objeto, existen otras tres tablas más, que se interrelacionan con ella. Estas tres tablas describen las tres formas de epigrafía que normalmente aparecen en las ánforas. Así, tenemos una tabla para sellos, una para grafitos y una para tituli picti. De este modo el proceso que sigue un objeto para su documentación es el siguiente. Comprobada la existencia de epigrafía en el ejemplar, se abre una ficha en la tabla Objeto. Una vez hecho esto, se abrirán tantas fichas en la tabla sello como sellos conserve el ejemplar, tantos fichas en la tabla grafito como grafitos conserve el ejemplar y tantas fichas en la tabla tituli picti como conserve el ejemplar. Todas las fichas se enlazan entre sí a través del mismo número de inventario que se da al ejemplar tanto en la tabla objeto como en el resto de tablas: sellos, grafitos y tituli picti. De este modo, cuando se consulta a la base de datos sobre un ejemplar determinado la respuesta mostrará de forma conjunta toda la información acumulada en las diferentes tablas. En la Tabla Sellos se inserta información referente a la posición que el sello ocupa en el objeto, la dirección del texto, el relieve de las letras o la forma y atributos de la cartela en la que suele aparecer inscrito. También se ha desarrollado un sistema diacrítico sencillo para codificar las características epigráficas formales de los sellos. Su finalidad es facilitar al máximo posible tanto la búsqueda en la base de datos de los sellos por su texto como su ordenación en un informe de resultados alfabéticos. La información de la tabla tituli picti es muy parecida a la de la tabla sellos. Se trata de información relativa a la tinta con la que fue pintado, la posición del titulus, la transcripción del texto, etc. Se pretende que la tabla sea lo más flexible posible. Del mismo modo, la tabla grafitos describe los atributos relativos a este tipo de epigrafía. El sistema de documentación dispone también de dos FAQ’s (Frequently Asked Questions), las preguntas más frecuentes que tienen los visitantes de un sitio web. En la primera de nuestras FAQ’s se explica con claridad cómo digitalizar y tratar las imágenes (tanto fotos como dibujos) de los diferentes objetos (ánforas) y epigrafía (sellos, tituli y grafitos) que constituyen la base de datos. De esta forma se pretende homogeneizar la calidad y formato de las imágenes de la base de datos. En la segunda FAQ se explica cómo se debe vaciar el contenido epigráfico de una publicación. En esta FAQ también se explican otros aspectos. Por ejemplo, cómo consultar la base de datos bibliográfica para comprobar que la publicación que se quiere vaciar no ha sido ya trabajada por otro colaborador; la forma en la que se debe pedir al webmaster el alta de una nueva publicación o cómo se debe planificar el trabajo de vaciado propiamente dicho de la epigrafía contenida en dicha publicación. Finalmente, tras el control de la calidad de los datos añadidos por el colaborador, el supervisor dará el visto bueno para que los nuevos datos puedan entrar a formar parte de la base. Estos datos, cuando sean consultados a través de Internet, aparecerán siempre indicando el colaborador-investigador que introdujo el dato y el supervisor que controló la calidad del mismo. Con ello se consiguen dos objetivos. Primero, que el trabajo de cada uno se vea reflejado en la base de datos y segundo que la calidad de cada dato introducido tenga un responsable claramente definido.
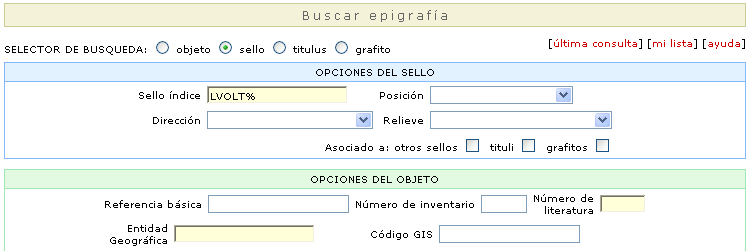
Además de las FAQ’s la base de datos también dispone de un área de descarga. Actualmente hay dos archivos descargables que sirven al colaborador en su trabajo de vaciado. El primer archivo, en formato MS Excel, es una plantilla que viene dotada de las tablas de códigos necesarias para que el colaborador pueda vaciar con facilidad la bibliografía seleccionada con anterioridad. El segundo es un archivo-plantilla en Adobe Photoshop, que permite al colaborador trabajar los dibujos o las fotografías de la epigrafía que se quiere vaciar con el estándar de calidad requerida en la base de datos. Finalmente, existe un archivo en formato MS Word que permite a los supervisores la elaboración de la ficha descriptiva de los diferentes tipos de objetos. 2.- Simulación sencilla. Para ejemplificar el proceso de búsqueda en la base de datos vamos a ver los pasos que debe seguir un invitado para consultar un epígrafe en concreto. En primer lugar, el invitado debe entrar en la base de datos tecleando su password. Una vez ha entrado, puede llegar a encontrar el epígrafe a partir de tres caminos diferentes: la búsqueda directa del epígrafe mediante la pantalla de búsqueda de epigrafía, la búsqueda a través del navegador geográfico o la búsqueda a través del navegador bibliográfico. En este caso, vamos a buscar un sello LVOLTEIL. En la primera opción, el invitado puede entrar una parte del texto LVOLT% del sello en la casilla correspondiente.
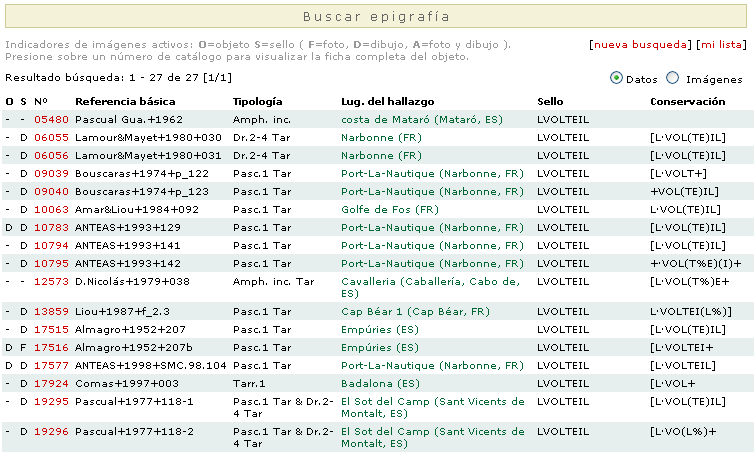
Aparecerá un listado de ejemplares que cumplen la condición de búsqueda.
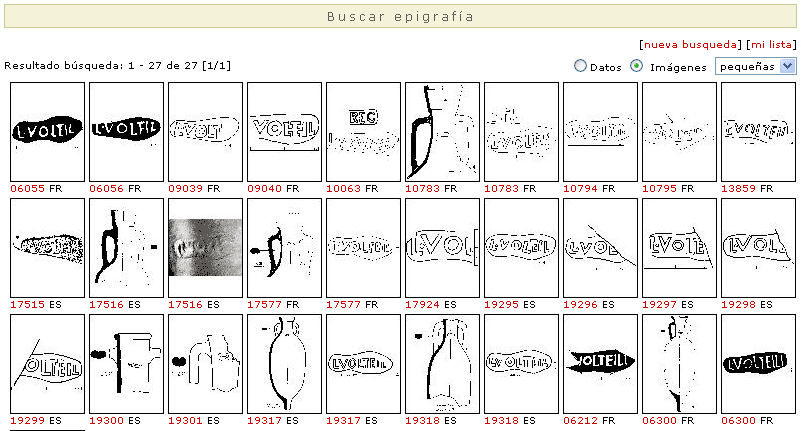
La lista puede verse en modo detallado (arriba) o en modo imágenes (abajo).
Seguidamente podrá escoger el ejemplar específico que se busca, en este caso el ejemplar 10783.
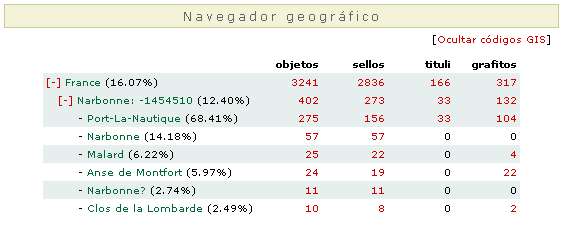
En la segunda opción, el investigador puede buscar a partir de un sistema de navegación “geográfica”. Este sistema estará en funcionamiento temporalmente, mientras se implementa definitivamente en nuestro sistema la herramienta SIG/GIS, implementación que está prevista para los próximos años. Mientras tanto, el navegador geográfico permite seleccionar un país, una región de éste o una entidad geográfica aún más limitada para llegar al mismo resultado que con el sistema anterior; se puede observar en la figura que junto a cada localidad aparece como código GIS el código numérico definido por GEOnet.
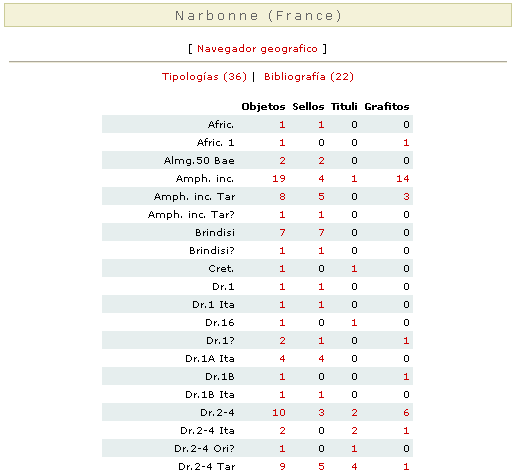
Finalmente, aparece el listado de la información que la base de datos atesora sobre "Narbonne" y los topónimos agregados. Si insistimos en escoger el topónimo principal Narbonne, la máquina nos devolverá esta tabla resumen con el número de tipologías anfóricas de Narbonne y el número de referencias bibliográficas que las publican.
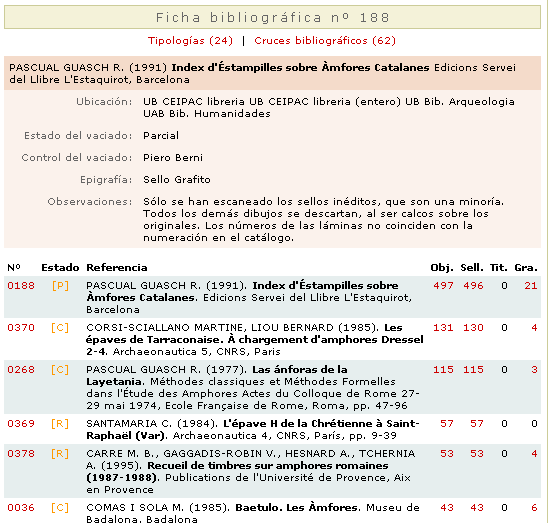
En la tabla propiamente dicha podemos ver el desglose por tipologías y el número de ejemplares, sellos, grafitos y tituli picti que contiene la base de datos. Todos y cada uno de los elementos que aparecen en la pantalla son enlaces que permiten seguir navegando por la base de datos. Así, pulsando en el valor "5" de la intersección "Dr.2-4 Tar" con "Sellos", optaríamos por escoger los 5 sellos sobre Dr.2-4 tarraconense que hay en Narbonne. El resultado sería esta otra pantalla que muestra estos sellos en forma de lista. Si seleccionamos este ejemplar, volveremos a la ficha individual del epígrafe que ya hemos visto antes. Pero la flexibilidad de la base de datos no se queda aquí. La interacción de la base de datos se demuestra con lo que hemos dado en denominar cruces bibliográficos. Con este nombre denominamos la posibilidad de seleccionar una referencia bibliográfica a partir de una ficha cualquiera y ver el número y calidad de información que contuvo dicha referencia bibliográfica. Así, si abrimos la ficha epigráfica del objeto 17527, podemos ver la lista de referencias bibliográficas que han publicado o citado dicha inscripción a lo largo del tiempo.
Si escogemos la refrencia bibliográfica "0118" de R. Pascual, por ejemplo, podremos ver una lista con todas las publicaciones que se cruzan con esta.
También vemos que la misma ficha bibliográfica indica que existen 62 cruces bibliográficos (arriba). Al seleccionar esta opción bibliográfica resultará una lista con las 62 referencias bibliográficas y junto a ellas aparece el número de objetos, sellos y tituli picti que publicó cada una de estas referencias. Y podemos seguir navegando por el interior de la base de datos de forma indefinida. Estos ejemplos son una clara muestra de la flexibilidad de nuestra base de datos para interrogar a la información desde distintos ángulos. En realidad, la base CEIPAC permite la interacción de todos sus elementos de una forma que facilita enormemente el acceso a la información y sobre todo el estudio, incluido el historiográfico. Saber seguir el rastro de una inscripción es uno de los mayores problemas con los que contamos y que creemos haber resuelto con nuestra base de datos. A pesar de que la base de datos es perfectamente operativa desde hace años, nuestros objetivos no se frenan aquí. En la actualidad estamos investigando la posibilidad de que la base de datos cree, de forma semiautomática, lo que hemos dado en denominar diccionarios prosopográficos. Se trataría de que los especialistas, a partir de la información acumulada en la base de datos, puedan estudiar y elaborar un diccionario prosopográfico de todos los individuos que aparecen en la epigrafía anfórica, estudiando sus cronologías, sus actividades comerciales, etc. Nuestro proyecto tampoco se quiere reducir a la base de datos. Así, pretendemos crear foros de debate, grupos de noticias, etc. También pretendemos que la base de datos sea una herramienta de docencia. Al comienzo hemos dicho que este espacio común permite que la documentación, los recursos y la metodología para gestionar la base de datos se conviertan en las herramientas didácticas que formen a nuevos investigadores. Creemos pues haber creado un instrumento que facilita la catalogación de la epigrafía anfórica y los estudios de historia económica y social que ella permite. Para finalizar, quisiera insistir en la idea de que ésta es una base de datos abierta a la colaboración de quien lo desee. Nuestra investigación se incluye dentro del proyecto Corpus Intertacional des Timbres Amforiques de la Union Academique Internationale. Existe ya una amplia red de colaboración con universidades e instituciones de otros países y esperamos que esta se amplíe, les invitamos a ello. |